HBase源码分析6—HFile剖析
在上一篇中我们介绍了一下BloomFilter的相关内容,这部分内容对于我们理解HFile的结构很重要(其实也没那么重要,跳过不看就是了= =||)。这一篇我们就来针对HFile下手,研究下他的结构究竟是什么样的。
历史
HFile一共经历了三个版本的变迁。我们有必要先了解下每次修改的缘由。
(在HFile出现前还有基于MapFile的解决方案,因为当时并没有HFile这个东西,就不提了。Compaction和标记删除就是那个时候出现的。)
V1
从JIRA(HBASE-61)上看,HFile的出现似乎是为了挖掘潜在的性能优化能力。在V1中,data和index保存在同一个文件中,支持保存metadata(如BloomFilter),FileInfo用于保存合并等场景需要的文件信息。

图片来自hbase.apache.org
V2
随着数据量的变大,V1的缺点也逐渐暴露出来:每个HFile中的索引等信息必须全部加载到内存中,这些数据有时会很大。在V2中主要引入了多级索引,不需要把所有索引加载到内存、块级索引等。

在这个图中:
- Scanned Block Section:顺序扫描时使用的块,包括了data block、leaf index block、bloom block
- Non-Scanned Block Section:顺序扫描时不使用的块,包括了meta block、intermediate data block等
- Load-on-Open Section:启动时需要被加载到内存的块,包括root data index、meta index、file info等
- Trailer:记录HFile基本信息和上面三个块的偏移量等信息
Block
HFileBlock
所有的块(跟data block同级的这些)都继承自HFileBlock(位置在 main/java/org/apache/hadoop/hbase/io/hfile/HFileBlock.java ),结构如下图

BlockType 表示了这个块的类型。HBase提供了以下几种类型( MagicStr 就是实际填在 BlockType 位置的数据)

BlockType 这个类里还定义了一些基本的读写操作,比较简单不列举了。
HFile是如何被读的呢?可以看同一个包下 HFileReaderV2.java ,在构造的时候有一个循环
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
while (offset < end) { if (Thread.interrupted()) { break; } // Perhaps we got our block from cache? Unlikely as this may be, if it happens, then // the internal-to-hfileblock thread local which holds the overread that gets the // next header, will not have happened...so, pass in the onDiskSize gotten from the // cached block. This 'optimization' triggers extremely rarely I'd say. long onDiskSize = prevBlock != null? prevBlock.getNextBlockOnDiskSize(): -1; HFileBlock block = readBlock(offset, onDiskSize, true, false, false, false, null, null); prevBlock = block; offset += block.getOnDiskSizeWithHeader(); } |
追踪 readBlock 这个函数可以追到 HFileBlock.java 中的 readBlockDataInternal ,比较简单,先读header,然后根据长度建一个新的buffer,把header拷贝过去,再把data读到buffer的后面。但是上面这个函数里block搞出来也没有下一步动作,其实是都整个被缓存起来了。代码在 readBlock函数中
|
1 2 3 4 5 6 7 8 9 10 |
// Cache the block if necessary if (cacheBlock && cacheConf.shouldCacheBlockOnRead(category)) { cacheConf.getBlockCache().cacheBlock(cacheKey, cacheConf.shouldCacheCompressed(category) ? hfileBlock : unpacked, cacheConf.isInMemory(), this.cacheConf.isCacheDataInL1()); } if (updateCacheMetrics && hfileBlock.getBlockType().isData()) { HFile.DATABLOCK_READ_COUNT.increment(); } |
下面我们挑几个block来分析下
HFileBlockIndex
HFileBlockIndex 是所有index的实现,里面提供了针对多层index和单层index的不同方法。比如在HFileReaderV2中
|
1 2 3 4 5 6 7 8 9 10 |
// Data index. We also read statistics about the block index written after // the root level. dataBlockIndexReader.readMultiLevelIndexRoot( blockIter.nextBlockWithBlockType(BlockType.ROOT_INDEX), trailer.getDataIndexCount()); // Meta index. metaBlockIndexReader.readRootIndex( blockIter.nextBlockWithBlockType(BlockType.ROOT_INDEX), trailer.getMetaIndexCount()); |
分析两个read的代码,总结出index block的data块格式大概如下,其中红色的中位信息只在data index中有,meta index里是没有的。具体有多少个blockEntry是从Trailer块里读出来的。
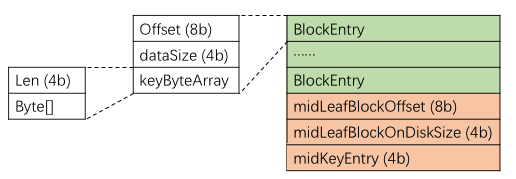
另外作为Index Block,这个类里面还提供了很多跟index相关的方法。比如我们挑这个类里面最长也是覆盖面最广的方法 loadDataBlockWithScanInfo ,这个方法的目的是搜索含有指定key的Data Block(和一些附加信息),代码如下(太长,折叠了)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
public BlockWithScanInfo loadDataBlockWithScanInfo(Cell key, HFileBlock currentBlock, boolean cacheBlocks, boolean pread, boolean isCompaction, DataBlockEncoding expectedDataBlockEncoding) throws IOException { int rootLevelIndex = rootBlockContainingKey(key); if (rootLevelIndex < 0 || rootLevelIndex >= blockOffsets.length) { return null; } // the next indexed key Cell nextIndexedKey = null; // Read the next-level (intermediate or leaf) index block. long currentOffset = blockOffsets[rootLevelIndex]; int currentOnDiskSize = blockDataSizes[rootLevelIndex]; if (rootLevelIndex < blockKeys.length - 1) { nextIndexedKey = new KeyValue.KeyOnlyKeyValue(blockKeys[rootLevelIndex + 1]); } else { nextIndexedKey = KeyValueScanner.NO_NEXT_INDEXED_KEY; } int lookupLevel = 1; // How many levels deep we are in our lookup. int index = -1; HFileBlock block; while (true) { if (currentBlock != null && currentBlock.getOffset() == currentOffset) { // Avoid reading the same block again, even with caching turned off. // This is crucial for compaction-type workload which might have // caching turned off. This is like a one-block cache inside the // scanner. block = currentBlock; } else { // Call HFile's caching block reader API. We always cache index // blocks, otherwise we might get terrible performance. boolean shouldCache = cacheBlocks || (lookupLevel < searchTreeLevel); BlockType expectedBlockType; if (lookupLevel < searchTreeLevel - 1) { expectedBlockType = BlockType.INTERMEDIATE_INDEX; } else if (lookupLevel == searchTreeLevel - 1) { expectedBlockType = BlockType.LEAF_INDEX; } else { // this also accounts for ENCODED_DATA expectedBlockType = BlockType.DATA; } block = cachingBlockReader.readBlock(currentOffset, currentOnDiskSize, shouldCache, pread, isCompaction, true, expectedBlockType, expectedDataBlockEncoding); } if (block == null) { throw new IOException("Failed to read block at offset " + currentOffset + ", onDiskSize=" + currentOnDiskSize); } // Found a data block, break the loop and check our level in the tree. if (block.getBlockType().isData()) { break; } // Not a data block. This must be a leaf-level or intermediate-level // index block. We don't allow going deeper than searchTreeLevel. if (++lookupLevel > searchTreeLevel) { throw new IOException("Search Tree Level overflow: lookupLevel="+ lookupLevel + ", searchTreeLevel=" + searchTreeLevel); } // Locate the entry corresponding to the given key in the non-root // (leaf or intermediate-level) index block. ByteBuffer buffer = block.getBufferWithoutHeader(); index = locateNonRootIndexEntry(buffer, key, comparator); if (index == -1) { // This has to be changed // For now change this to key value KeyValue kv = KeyValueUtil.ensureKeyValue(key); throw new IOException("The key " + Bytes.toStringBinary(kv.getKey(), kv.getKeyOffset(), kv.getKeyLength()) + " is before the" + " first key of the non-root index block " + block); } currentOffset = buffer.getLong(); currentOnDiskSize = buffer.getInt(); // Only update next indexed key if there is a next indexed key in the current level byte[] tmpNextIndexedKey = getNonRootIndexedKey(buffer, index + 1); if (tmpNextIndexedKey != null) { nextIndexedKey = new KeyValue.KeyOnlyKeyValue(tmpNextIndexedKey); } } if (lookupLevel != searchTreeLevel) { throw new IOException("Reached a data block at level " + lookupLevel + " but the number of levels is " + searchTreeLevel); } // set the next indexed key for the current block. BlockWithScanInfo blockWithScanInfo = new BlockWithScanInfo(block, nextIndexedKey); return blockWithScanInfo; } |
首先从通过 rootBlockContainingKey 查他在root index中的位置,这个是通过在blockkeys数组中做二分查找实现的(blockkeys存储的是每个块的最小的key)。然后通过一个while循环一层一层往下找,如果当前层是data block就退出循环,否则(就是intermediate index block)调用 locateNonRootIndexEntry 查找下一层的block,这里面又是一个二分查找。最后组装一下data block的信息返回。
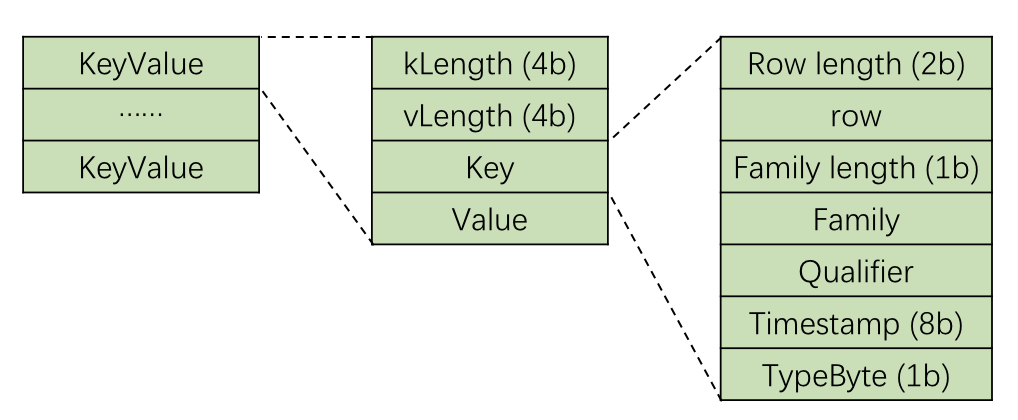
Data Block
从 HFileReaderV2 初始化代码中我们可以找到这个片段,是跟data block解析相关的
|
1 2 3 |
// Read data block encoding algorithm name from file info. dataBlockEncoder = HFileDataBlockEncoderImpl.createFromFileInfo(fileInfo); fsBlockReaderV2.setDataBlockEncoder(dataBlockEncoder); |
意思说是根据fileInfo的信息设置合适的encoder。在 createFromFileInfo 这个方法中又有
|
1 2 3 |
if (encoding == DataBlockEncoding.NONE) { return NoOpDataBlockEncoder.INSTANCE; } |
这个 NoOpDataBlockEncoder.INSTANCE 就是raw数据的encoder了,也就是不做任何的encoding和decoding。继续追进去在 startBlockEncoding 方法中我们可以发现实际的encoder是 NoneEncoder 。通过对这个类的分析,我们很容易得到data block的上层结构。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public int write(Cell cell) throws IOException { int klength = KeyValueUtil.keyLength(cell); int vlength = cell.getValueLength(); out.writeInt(klength); out.writeInt(vlength); CellUtil.writeFlatKey(cell, out); out.write(cell.getValueArray(), cell.getValueOffset(), vlength); int size = klength + vlength + KeyValue.KEYVALUE_INFRASTRUCTURE_SIZE; // Write the additional tag into the stream if (encodingCtx.getHFileContext().isIncludesTags()) { int tagsLength = cell.getTagsLength(); out.writeShort(tagsLength); if (tagsLength > 0) { out.write(cell.getTagsArray(), cell.getTagsOffset(), tagsLength); } size += tagsLength + KeyValue.TAGS_LENGTH_SIZE; } if (encodingCtx.getHFileContext().isIncludesMvcc()) { WritableUtils.writeVLong(out, cell.getSequenceId()); size += WritableUtils.getVIntSize(cell.getSequenceId()); } return size; } |
追 CellUtil.writeFlatKey(cell, out); 代码,可以看出key的结构
|
1 2 3 4 5 6 7 8 9 10 11 |
public static void writeFlatKey(Cell cell, DataOutputStream out) throws IOException { short rowLen = cell.getRowLength(); out.writeShort(rowLen); out.write(cell.getRowArray(), cell.getRowOffset(), rowLen); byte fLen = cell.getFamilyLength(); out.writeByte(fLen); out.write(cell.getFamilyArray(), cell.getFamilyOffset(), fLen); out.write(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()); out.writeLong(cell.getTimestamp()); out.writeByte(cell.getTypeByte()); } |
结构如下图